


Have you heard of web scraping before? Have you sourced for your dataset before?
Data scraping is a process of gathering data or information from the web/internet. It's an underrated aspect of data science in the aspect that, most data used are available either on Kaggle, analytic vidya and the rest. But in the case whereby you want to build a model from scratch or you need to get an insight on a dataset tailored to a specific area or people, to achieve close to a perfect result, getting your dataset yourself is the best way.
Your dataset can be sourced from different places depending on what exactly you are building. Could be from a website, social media and so on. Data on the internet and web page are mostly unstructured and to get the full value of such data, its got to be in a structured format and there comes in the term WEB/DATA SCRAPING.
To extract your data from the web, there are tools designed for that. It could be software is known as web scrapers, the likes of Octoparse, Parse Hub and Co. Using software actually make data extraction easier and faster without the need to write codes, it's like a cheat mode to extract data but there's a limitation and can be complex.
Some prefer the codes way and there are libraries in python designed specifically for that. The likes of beautiful Soup, Selenium etc.
Now to the business... PARSEHUB
Parse hub really is a cool web scraper, easy to navigate and use. The interface is user friendly and it's easy to understand. The features include tutorials on how to navigate the scraper.
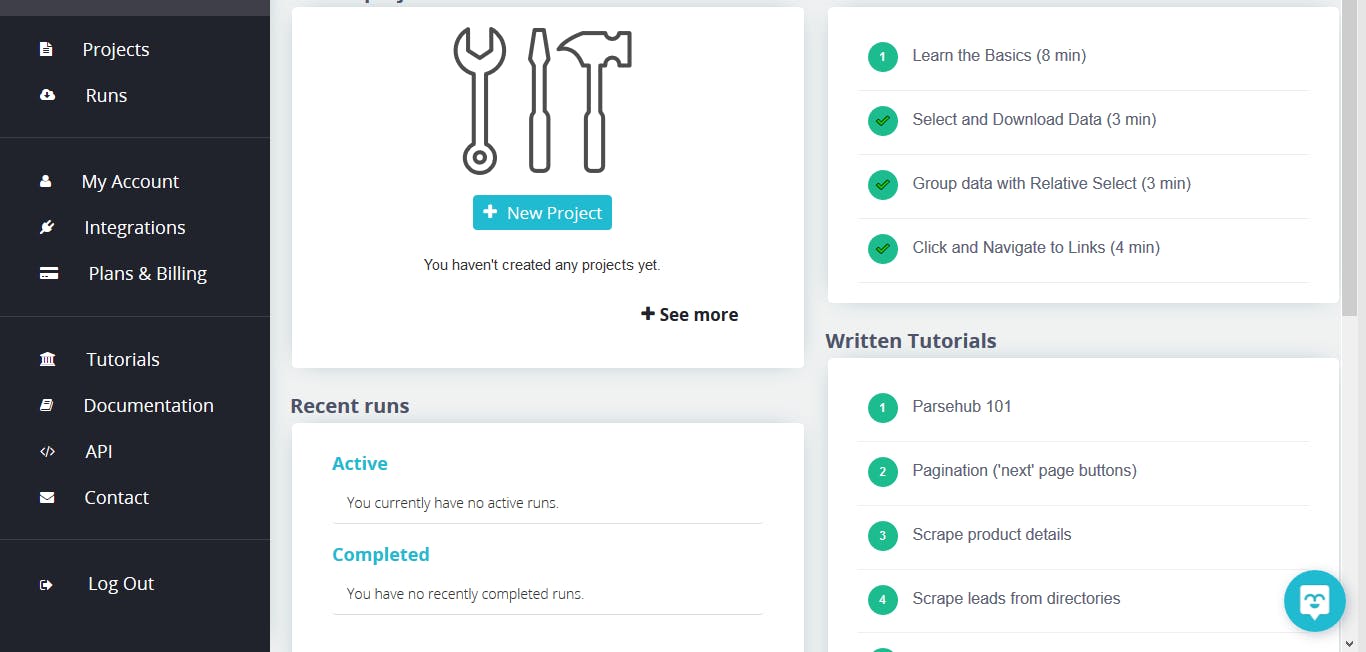
To start a new project, click on add project and a new page shows.
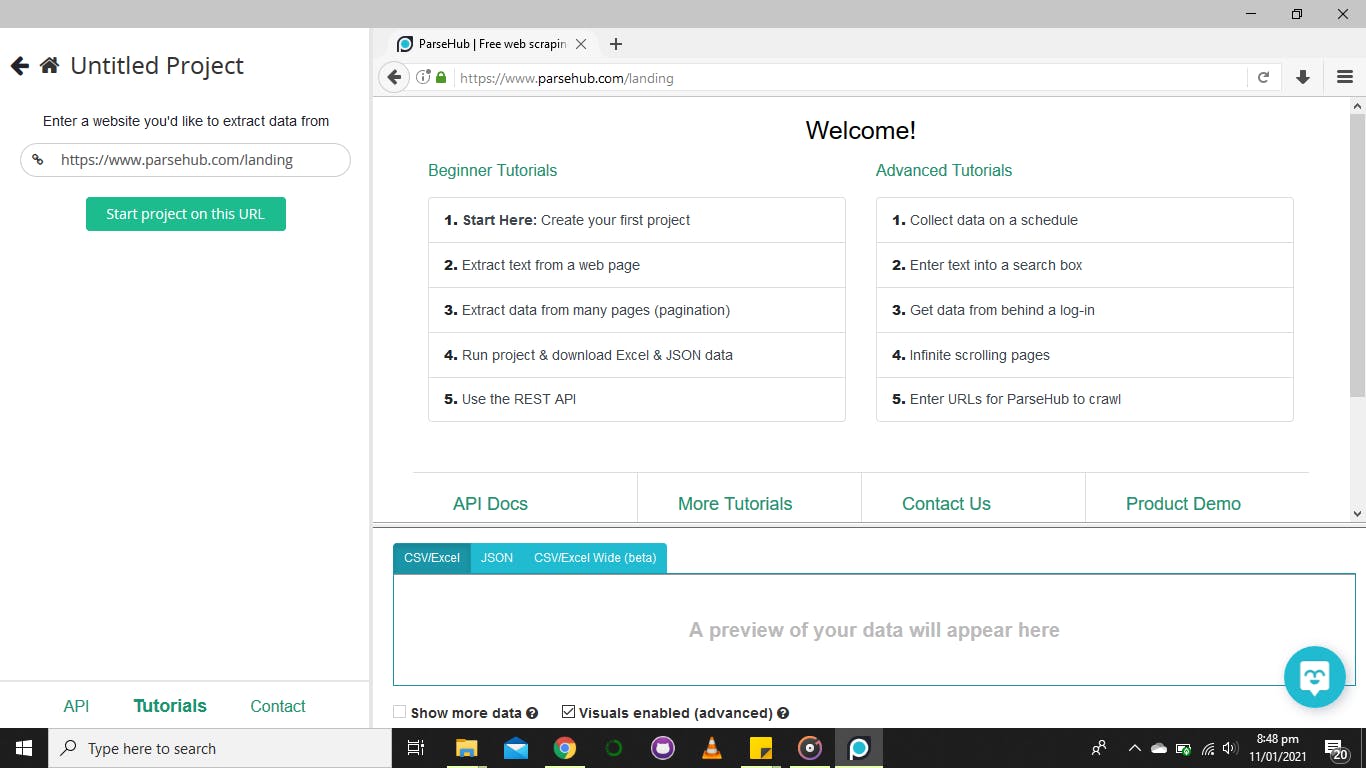
To extract from a website, include the URL of the website in the space provided on the left side that states enter your website and click on the start project icon.
A sample URL to demonstrate.
After loading your URL, it shows a sample page like this
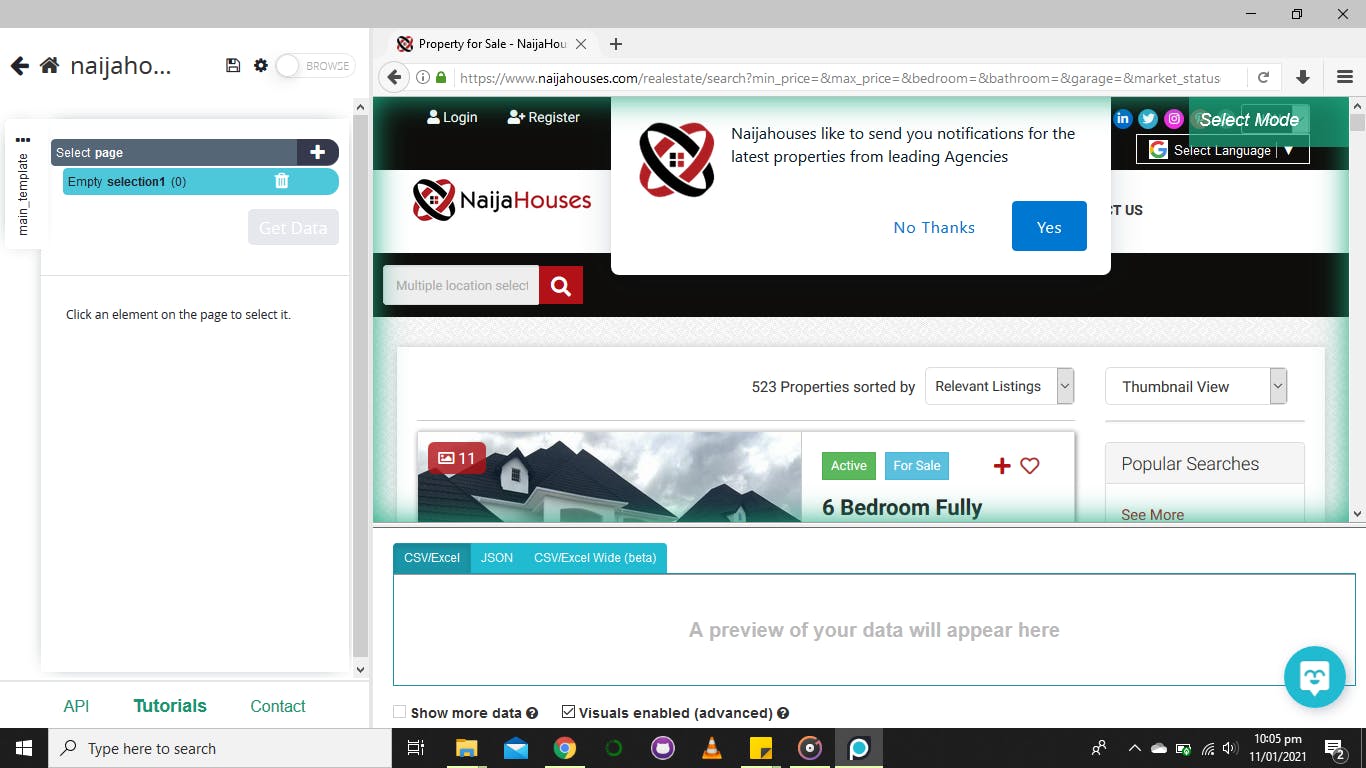
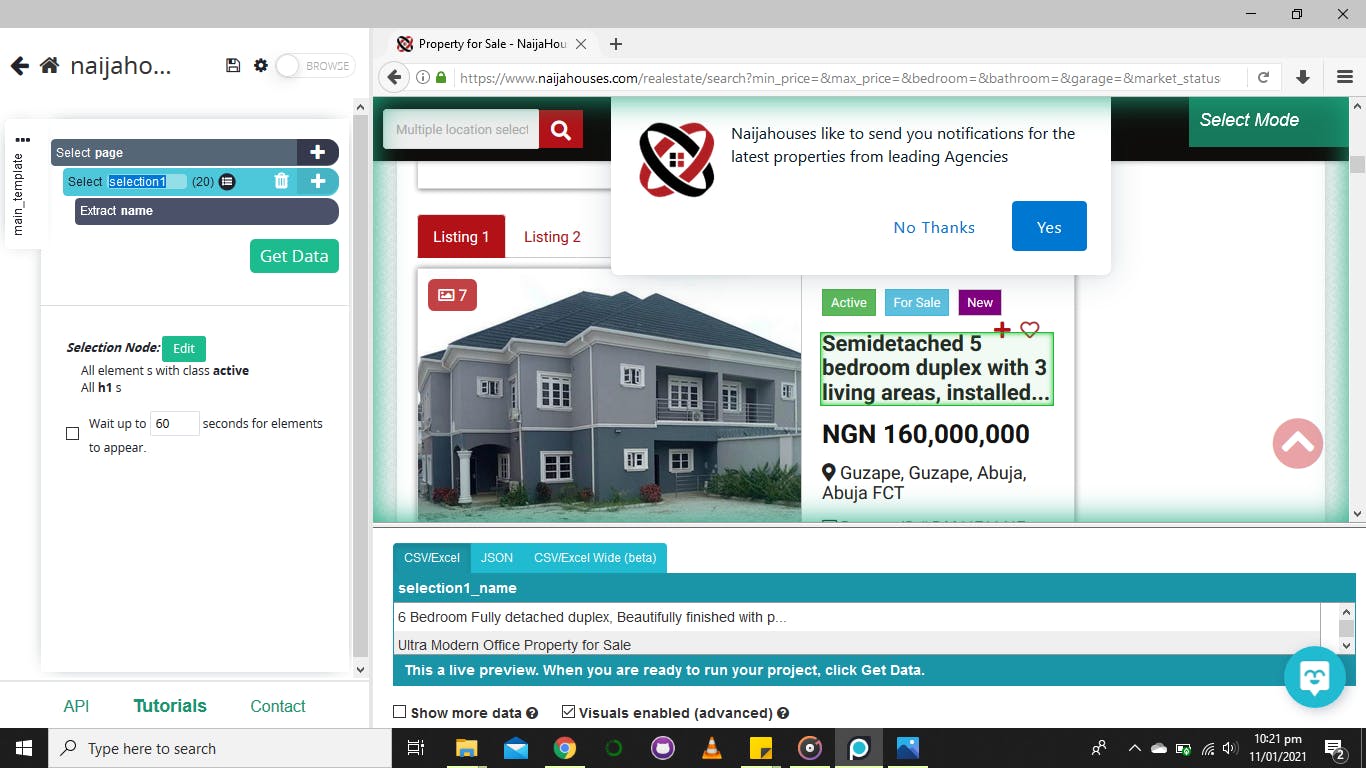
The left part shows the process of picking what data is needed from the website and a preview is shown at the bottom of the page. To start, click on any element on the loaded web page and this shows
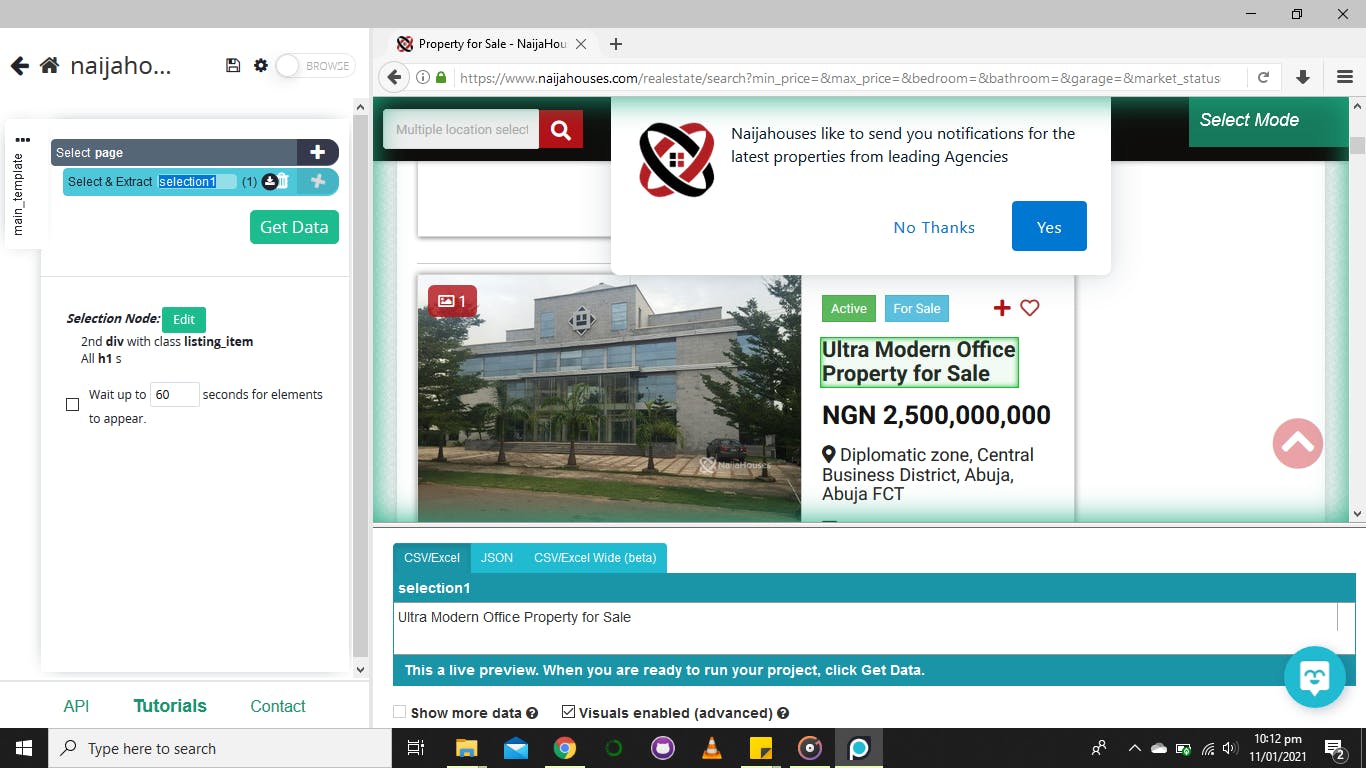 then click on a similar element for a different property to show that's what you are selecting as shown below.
then click on a similar element for a different property to show that's what you are selecting as shown below.
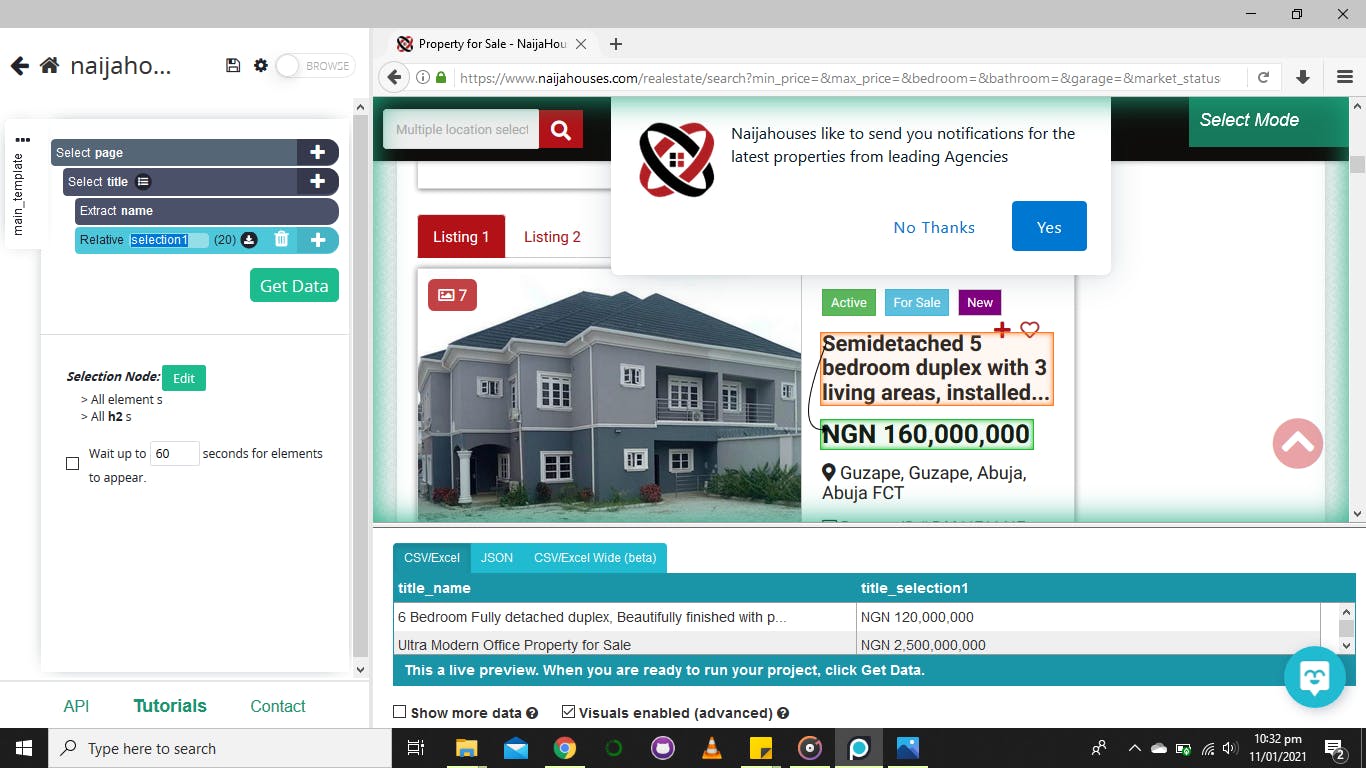
 The selection1 on the left side is changed to title and then click on the plus sign beside the select title and pick relative select.
Relative select is a way of connecting one element to the other.
Drag your arrow from the first element picked to the next element you need as shown below
The selection1 on the left side is changed to title and then click on the plus sign beside the select title and pick relative select.
Relative select is a way of connecting one element to the other.
Drag your arrow from the first element picked to the next element you need as shown below
 Click on the plus sign from the select title and repeat the same process of relative select and picking the element needed till the last element is picked.
Lastly, set pagination and get your data extracted either in CSV format/ JSON/API.
Click on the plus sign from the select title and repeat the same process of relative select and picking the element needed till the last element is picked.
Lastly, set pagination and get your data extracted either in CSV format/ JSON/API.
Now your data is ready to use, either for model building, visualization or the purpose it was scrapped for.
I hope this is helpful, let me know what you think in the comment section. See you.
